
Working with Transformer-based AI models often seems straightforward at first.
You create a client—whether through an SDK or a REST call—send a prompt, and the model returns an answer.
Simple. Or at least it appears that way.
But very quickly, every practitioner encounters the configuration parameters exposed by these models:
temperature, top_k, and top_p.
Most developers are comfortable adjusting temperature and can clearly see how it affects creativity and variability.
top_k is somewhat understood, although rarely used in practice.
And top_p—nucleus sampling—is the one parameter that consistently remains misunderstood, underused, or simply ignored.
I’ve seen this repeatedly in projects, customer workshops, and community discussions.
And honestly, early in my own AI journey, I was no different.
I knew these parameters existed, but beyond tweaking the temperature, I seldom touched top_k and almost never experimented with top_p.
Recently, a colleague asked me again why I was using a specific top_p value in an Azure OpenAI RAG pipeline, and that sparked the idea for this article.
If many developers still struggle with the meaning and impact of top_p, it’s worth demystifying—especially in enterprise scenarios.
In RAG solutions powered by Azure AI Search, understanding sampling isn’t a “nice to have”—it’s mission-critical for:
- Reducing hallucinations
- Keeping responses anchored in retrieved content
- Meeting compliance, audit, and quality requirements
- Ensuring predictable behavior in production workloads
Large language models like GPT don’t simply “pick” the next word—they sample from a probability distribution.
Each time you send a prompt, the model evaluates thousands of potential next tokens, assigns a probability to each, and then selects one based on its sampling strategy.
In Azure OpenAI, you influence this decision-making process through the parameters temperature, top_p (nucleus sampling), and depending on the model, top_k.
These controls determine whether your model behaves like a precise advisor—factual, consistent, deterministic—or a creative partner that explores diverse, surprising output patterns.
Understanding how and when to adjust these parameters is essential for building enterprise-grade AI solutions that are stable, trustworthy, and aligned with your organization’s requirements.
To make this easier to explore, I’ve also included a Python demo in the repository, where you can experiment interactively with logits, softmax, top_k, and top_p sampling:
👉 GitHub Repository:
https://github.com/charisal/azure-openai-llm-sampling-examples
Sampling Process
The diagram below illustrates the sampling process—how a model determines the next word in the incomplete sentence:
“This solution integrates modern …”
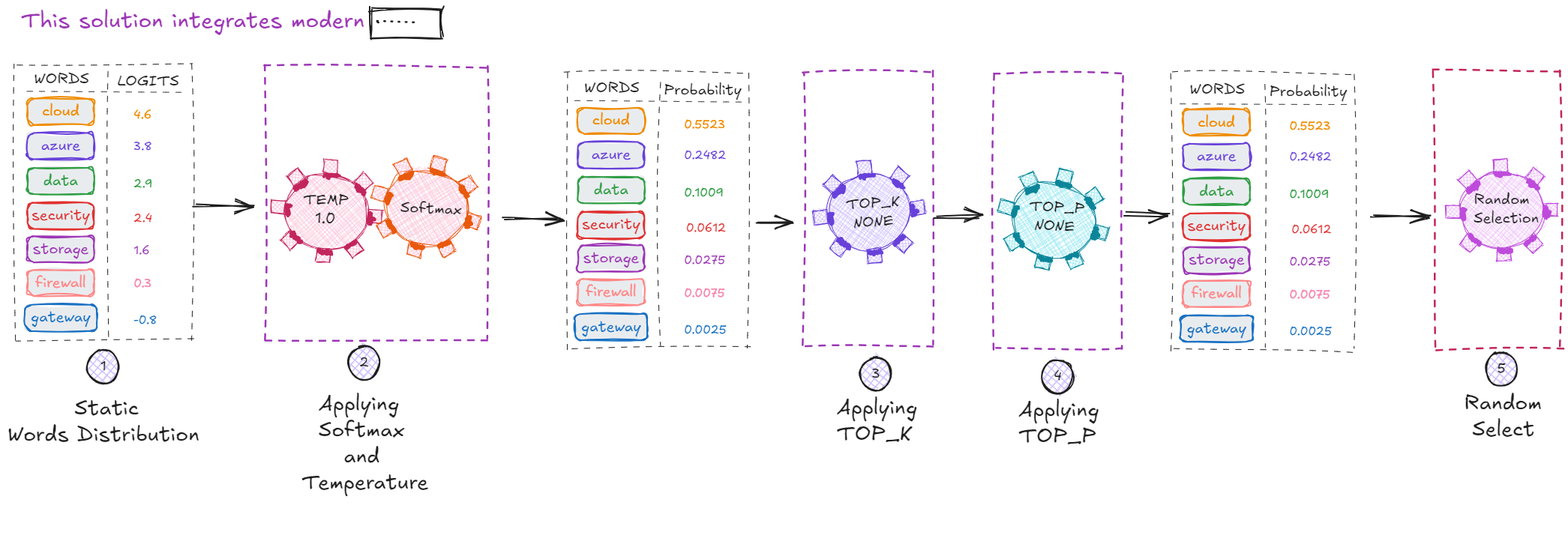
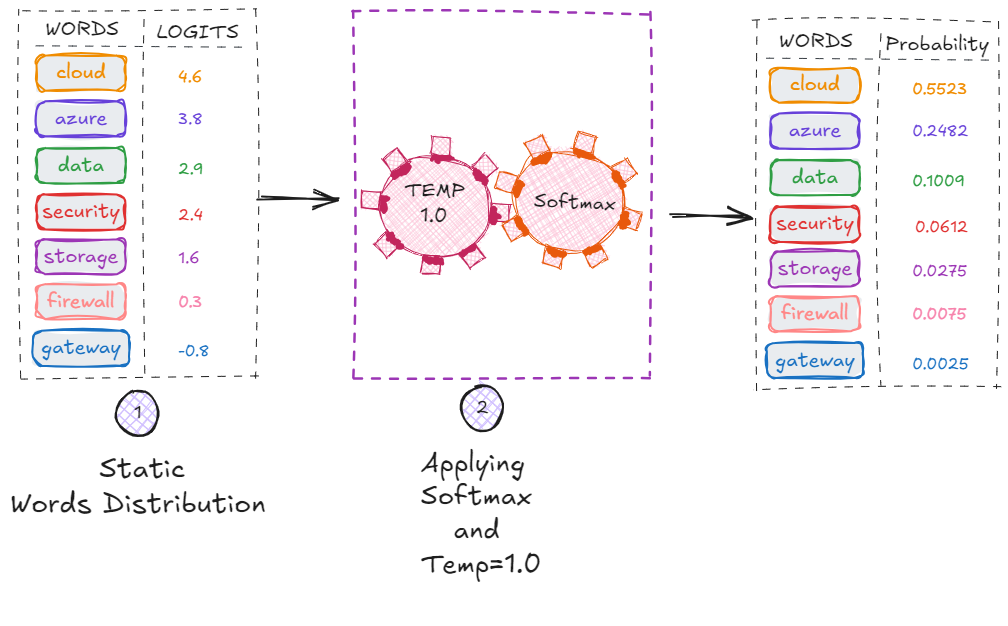
Step 1: The Model Produces Logits (Raw Scores)
The first step in token generation is the creation of logits—the raw, unnormalized scores produced by the neural network before converting them into probabilities.
Transformer-based models operate internally on these logits.
They represent the model’s raw preferences for each possible next word:
| Word | Logit |
|---|---|
| cloud | 4.6 |
| azure | 3.8 |
| data | 2.9 |
| security | 2.4 |
| storage | 1.6 |
| firewall | 0.3 |
| gateway | -0.8 |
| Words and Logits (Raw Scores) | |
Why Logits Instead of Probabilities?
Logits give the model more flexibility and numerical stability when shaping the probability distribution.
Key reasons:
- Logits preserve the raw scale of the model’s preferences
- Temperature is applied to logits, not probabilities
- Softmax on logits is numerically stable
- Training uses logits directly (gradient-based optimization)
- Probabilities alone lose important relative differences
Simplified intuition:
- Logits = the model’s raw thoughts
- Probabilities = the usable form for sampling
Step 2: Softmax Converts Logits Into Probabilities
Next, the logits are passed through the softmax function, which transforms them into a proper probability distribution.
Softmax ensures:
- All values become positive
- The entire distribution sums to exactly 1.0
- The model can use these values for sampling
The resulting probabilities might look like this:
| Word | Probability |
|---|---|
| cloud | 0.5523 |
| azure | 0.2482 |
| data | 0.1009 |
| security | 0.0612 |
| storage | 0.0275 |
| firewall | 0.0075 |
| gateway | 0.0025 |
| Words and Probabilities | |
As expected, the sum of all probabilities equals 1.0
Step 3: Applying Top-P and Top-K (Not Yet Applied Here)
Before sampling, the model may apply additional filtering:
- Top-K → keep only the K highest-probability tokens
- Top-P (nucleus sampling) → keep the smallest set of tokens whose cumulative probability ≥ P
In this example, neither is applied yet:
| Word | Probability |
|---|---|
| cloud | 0.5523 |
| azure | 0.2482 |
| data | 0.1009 |
| security | 0.0612 |
| storage | 0.0275 |
| firewall | 0.0075 |
| gateway | 0.0025 |
| Words and Probabilities | |
All tokens remain available for sampling.
Step 4: The Model Samples the Next Token
Now comes the important question:
Why doesn’t the model always choose the token with the highest probability?
(In this case, “cloud” with ~55% probability)
Because randomness makes language natural.
If the model always picked the top token:
- Every response would be identical
- Output would sound robotic
- The model could fall into loops
- Creativity would drop to zero
- Open-ended tasks would fail
- All users would receive the exact same responses
To avoid this, LLMs introduce controlled randomness, known as sampling.
You can remove randomness (temperature = 0), but by default the model samples from the distribution.
In our example, the model selected azure, even though cloud had the highest probability:
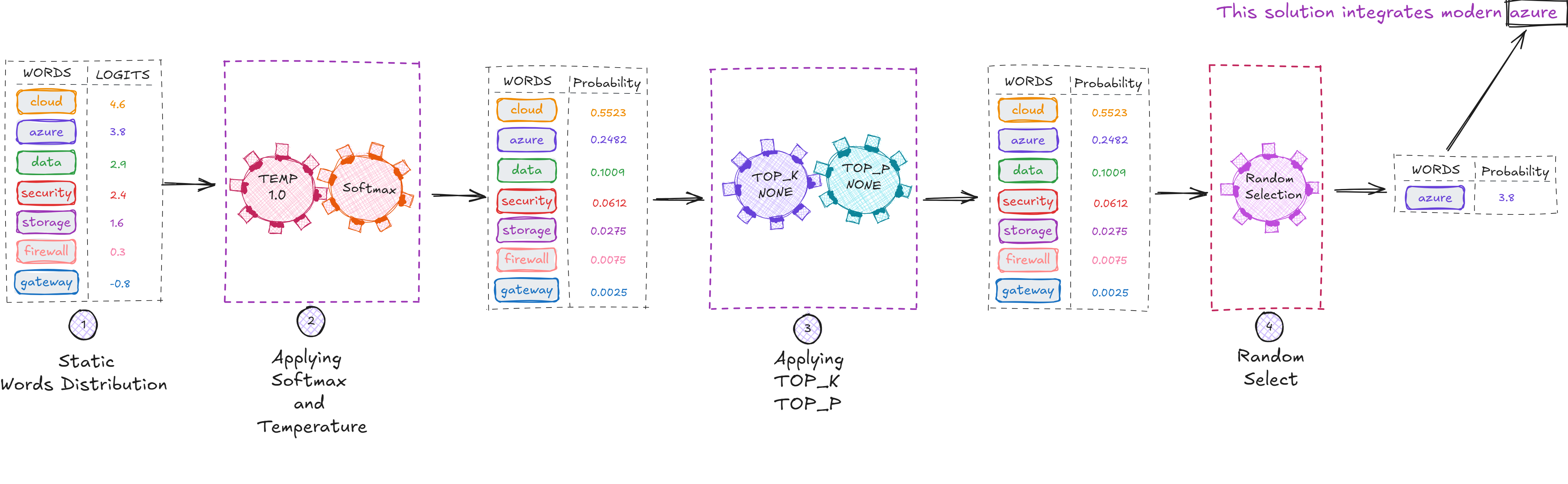
This is expected—and desirable—unless your task requires deterministic output.
So What Do Temperature, Top-K, and Top-P Actually Do?
These three parameters define how predictable or creative the model’s output will be.
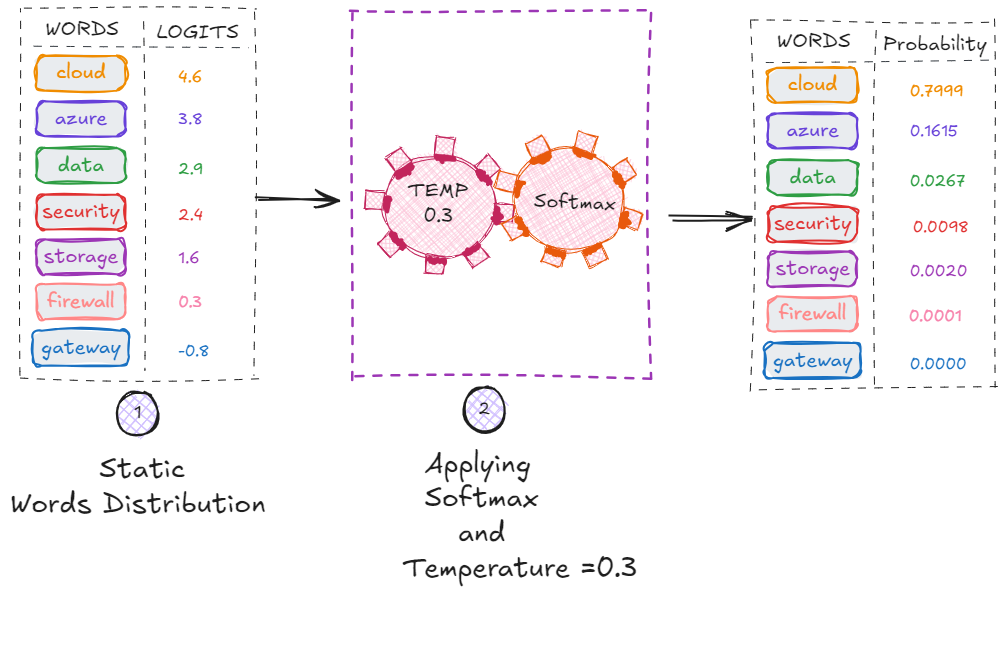
Temperature: How Adventurous the Model Feels
Temperature controls how “sharp” or “flat” the probability distribution becomes.
- Low temperature (0.0–0.3)
→ very conservative, predictable, deterministic
→ ideal for RAG and conversational accuracy
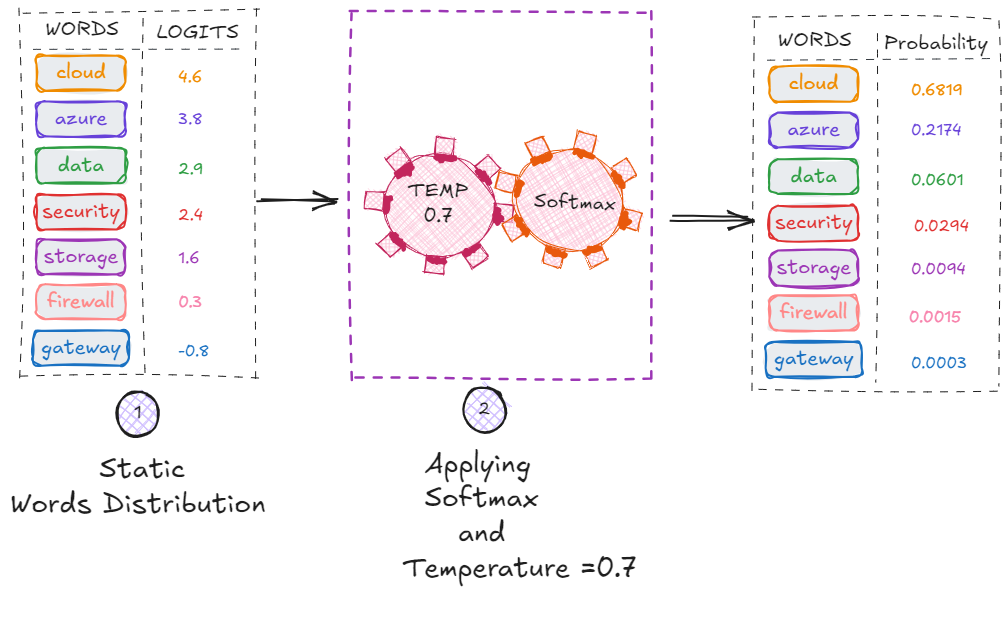
- Medium temperature (0.4–0.7)
→ balanced responses
→ good general conversational UX
- High temperature (0.8–1.0)
→ more creative, expressive, surprising , diverse
→ great for brainstorming, ideation and content generation
Intuition
Temperature affects logits before softmax. Lower temperature exaggerates differences between tokens; higher temperature flattens the distribution.
For example, setting temperature to 0.1 would make the model almost always choose token cloud (the highest-probability token).
This is very small **temperature values ** is often the preferred setting for RAG pipelines in Azure AI Search—it gives predictable, repeatable answers grounded in your retrieved documents.
**Top-K: Limit Sampling to the Best K Tokens
Top_k keeps only the top k tokens by probability.
Example: top_k = 3 → Candidates are: cloud, azure, data
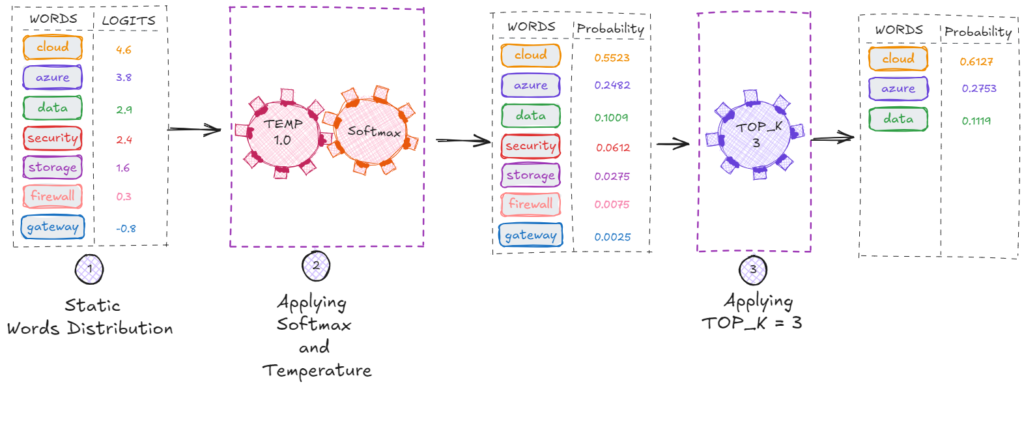
Best for:
- Strict control over randomness
- Domain-specific outputs
- Structured generation (SQL, code, JSON, etc.)
Top-P (Nucleus Sampling): Selecting a Probability Bubble
Top_p chooses tokens from the smallest set whose cumulative probability mass ≥ p.
Example with top_p = 0.9:
- cloud → 0.5523
- cloud + azure →0.8005
- cloud + azure + data → 0.904 → Stop (≥ 0.9)
Result: the candidate pool is cloud, azure and data
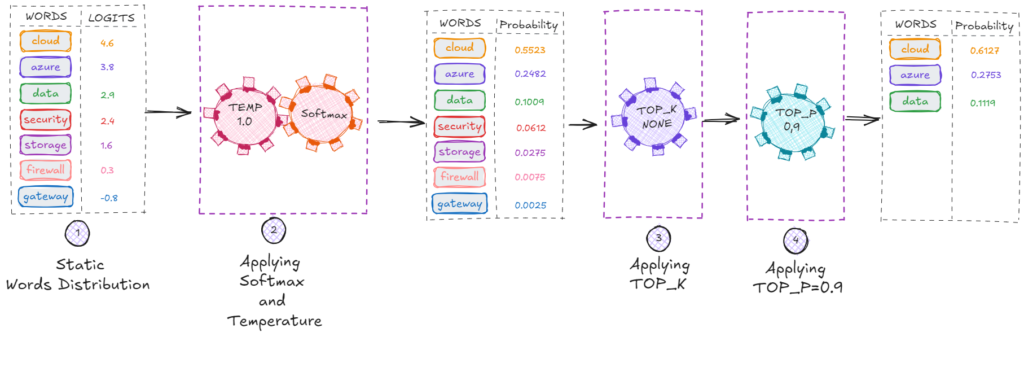
Unlike top_k, top_p adapts dynamically based on distribution shape.
This makes responses more stable, especially at higher temperatures.
Recommended values
- RAG: 0.7–0.95
- Chat apps: 0.8–0.95
- Creative tasks: 0.9–1.0
Best Practices for Azure AI Solutions
For RAG with Azure AI Search
- temperature: 0.0–0.3
- top_p: 0.7–0.95
- Keep output predictable
- Avoid high temperature to reduce hallucinations
- Use deterministic decoding for citations
For Chat Assistants
- temperature: 0.3–0.7
- top_p: 0.8–0.95
- Balance creativity and coherence
For Generative Creativity
- temperature: 0.8–1.3
- top_p: 0.9–1.0
- Encourage novelty and variation
Summary
Sampling fundamentally shapes how Azure OpenAI models behave:
- Temperature controls how adventurous or deterministic the model is.
- Top_p controls the size of the probability nucleus.
- Top_k restricts sampling to the highest-ranked candidates.
Together, these parameters determine whether the model is accurate, balanced, or creative.
Understanding these levers is essential for building:
- High-quality RAG solutions
- Reliable enterprise AI applications
- Effective copilots
- Engaging conversational agents
In enterprise AI—especially with Azure AI Search—it’s not enough for models to generate text.
They must generate the right text, with the right balance of stability and expression.
Sampling parameters give you that control.



