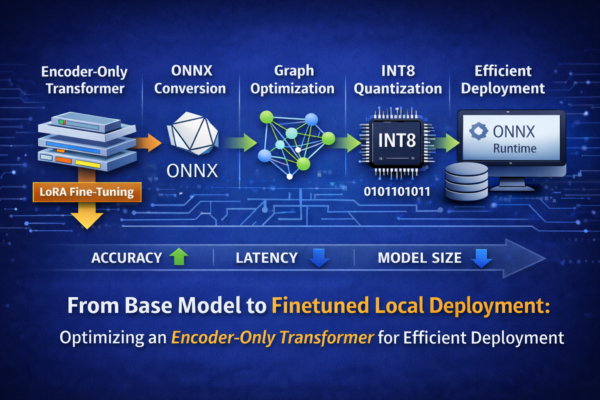
In this article, I walk through the complete deployment pipeline of an encoder-only Transformer model for text classification—from LoRA-based fine-tuning to ONNX conversion, graph optimization, and quantization. Each stage is analyzed in terms of its impact on accuracy, latency, and model size. The focus is on true local deployment: running a hardware-aware classification model entirely on local infrastructure using ONNX Runtime

From Hugging Face to Foundry Local: A Step-by-Step Guide with Microsoft Olive
Running Hugging Face models locally often requires more than a simple download. In this post, we walk through how to use Microsoft Olive to compile and optimize a model from the Hugging Face Hub into a Foundry Local–ready artifact. You will learn how Olive streamlines model conversion, optimization, and packaging, enabling efficient local inference across supported runtimes while maintaining performance and portability.

ONNX Runtime:Running ONNX Models on Any Hardware (Part 2)
In Part 1 of this series, we explored what ONNX is, why it was created, and how it decouples model training from deployment by providing a standardized, framework-agnostic model format. That foundation is essential for understanding the next step in the ONNX ecosystem.
In this article, we focus on ONNX Runtime—the execution engine that brings ONNX models to life. You will learn how ONNX Runtime loads and optimizes ONNX models, selects the appropriate execution provider, and runs inference efficiently across CPUs, GPUs, and NPUs.

ONNX: One Model Format for Cross-Platform Machine Learning Deployment (Part1)
ONNX (Open Neural Network Exchange) is an open standard designed to make machine learning models portable and interoperable across frameworks, tools, and hardware platforms. Its primary purpose is to decouple model training from model deployment, allowing models trained in popular frameworks such as PyTorch or TensorFlow to be exported into a common format and executed efficiently in different production environments.
This blog post is structured into two main parts. Part 1 focuses on ONNX, providing an overview of the standard, its design goals, and its role in enabling model portability and interoperability across machine learning frameworks. Part 2 covers ONNX Runtime, examining how ONNX models are executed in production, with an emphasis on performance optimization, hardware acceleration, and deployment considerations.

Understanding LLM Sampling: How Temperature, Top-K, and Top-P Shape next Word Selection in Azure OpenAI
Working with Transformer-based AI models often seems straightforward at first.You create a client—whether through an SDK or a REST call—send a prompt, and the model returns an answer.Simple. Or at least it appears that way. But very quickly, every practitioner encounters the configuration parameters exposed by these models:temperature, top_k, and top_p. Most developers are comfortable […]