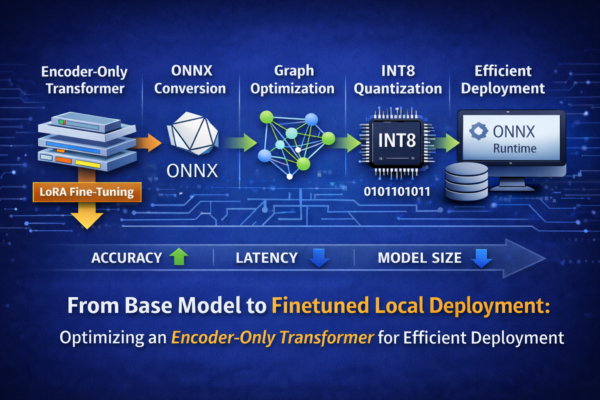
In this article, I walk through the complete deployment pipeline of an encoder-only Transformer model for text classification—from LoRA-based fine-tuning to ONNX conversion, graph optimization, and quantization. Each stage is analyzed in terms of its impact on accuracy, latency, and model size. The focus is on true local deployment: running a hardware-aware classification model entirely on local infrastructure using ONNX Runtime

From Hugging Face to Foundry Local: A Step-by-Step Guide with Microsoft Olive
Running Hugging Face models locally often requires more than a simple download. In this post, we walk through how to use Microsoft Olive to compile and optimize a model from the Hugging Face Hub into a Foundry Local–ready artifact. You will learn how Olive streamlines model conversion, optimization, and packaging, enabling efficient local inference across supported runtimes while maintaining performance and portability.

Running AI Locally with Microsoft AI Foundry Local: What You Need to Know
Microsoft AI Foundry Local enables organizations to run AI workloads locally, offering greater control over data, improved performance, and reduced reliance on cloud-only architectures. This post provides an introduction to the core concepts, architecture, and practical use cases of Microsoft AI Foundry Local for enterprise and developer scenarios.

Online Event: An Introduction to Microsoft AI Foundry Local
In this upcoming online session, I will introduce Microsoft AI Foundry Local and demonstrate how organizations can run AI workloads locally to improve performance, enhance data sovereignty, and reduce dependency on cloud-only architectures. As part of the Azure AI, Sentinel, and Copilot User Group, this talk provides practical insights into architecture, use cases, and getting started with local AI execution.

Why Local AI Matters: How to Choose the Right Model Size for Your Device
Learn how to choose the right local AI model size for your device. A beginner-friendly guide to RAM, VRAM, quantization, and running models like Phi-3.5 locally