
During a recent community meetup, I demonstrated Microsoft Foundry Local and walked through its high-level architecture, including where ONNX Runtime fits into the overall execution pipeline. While the demo itself focused on running models locally and efficiently, the discussion that followed quickly shifted in a different direction. Several questions were not about Foundry Local at all, but about ONNX: what it actually is, why it exists, and how it relates to the models and runtimes we use every day.
These questions revealed a common and very understandable gap. Many practitioners actively use tools that rely on ONNX—often indirectly through platforms, SDKs, or optimized runtimes—without ever needing to think about ONNX itself. As a result, ONNX is frequently perceived as “just another file format” or, even more confusingly, as something interchangeable with ONNX Runtime. In reality, ONNX plays a much more fundamental role in modern machine learning systems, especially at the boundary between training and deployment.
In this blog post, I aim to close that gap. Rather than approaching ONNX from a purely API-driven or framework-specific perspective, the focus is on the underlying concepts: what ONNX is, which problems it was designed to solve, and how it fits into the broader lifecycle of an AI model.
The AI Model Lifecycle
An AI model moves through a lifecycle that includes experimentation, training, validation, deployment, and long-term operation. While many tools and processes may be involved, this lifecycle can be divided into two fundamentally different phases: model training and model deployment.
The training phase is concerned with learning. Models are developed and optimized in flexible, dynamic environments that support rapid iteration. Engineers experiment with architectures, tune hyperparameters, and adjust objectives using capabilities that are essential during optimization but transient in nature.
Once training is complete, the lifecycle transitions into the deployment phase.
Deployment focuses on inference rather than learning. The primary concerns shift to execution efficiency, latency, resource usage, and operational stability. Models are expected to run reliably across a range of environments, often without access to the original training framework or a Python runtime.
This transition marks a conceptual boundary: the model is no longer something that is being constructed, but something that is being executed.
What a Trained Model Actually Is
At that boundary, the output of training is a trained model. Importantly, a trained model is not the code that produced it. Once training ends, the model becomes a static artifact that captures the result of optimization, not the training process itself.
Conceptually, this artifact consists of two components. The first is a computation graph that defines the sequence of mathematical operations applied during inference. The second is a set of trained parameters—such as weights, biases, and constants—that determine how those operations behave.
Neither component depends on the original training environment. The computation graph contains no training loops, gradient logic, or framework-specific control flow, and the parameters are simply numerical tensors. This allows a trained model to be stored, transferred, and executed as a self-contained artifact.
What Is ONNX and Why Does It Exist?
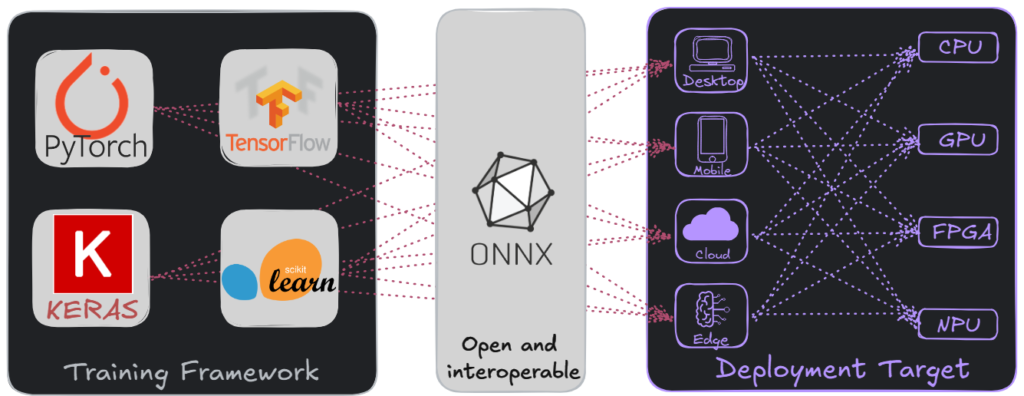
ONNX, which stands for Open Neural Network Exchange, is an open standard for representing trained machine learning and deep learning models in a framework-independent way. It defines a common, portable format that captures a model’s computation without tying it to a specific training framework, programming language, or execution environment.
The need for ONNX arises from a mismatch between how models are developed and how they are deployed. Model training typically happens in high-level frameworks such as PyTorch or TensorFlow, which are optimized for research productivity. These environments provide dynamic graphs, automatic differentiation, and Python-first APIs that are essential during experimentation.
Production environments, however, have different priorities. Deployed models must execute efficiently, with low latency and predictable performance, often on heterogeneous hardware such as CPUs, GPUs, NPUs, or edge devices. These environments frequently operate outside of Python and favor stability, portability, and long-term maintainability.
Before ONNX, trained models were tightly coupled to their training frameworks. Moving a model into production often required rewriting it, re-implementing it in another framework, or accepting unnecessary runtime overhead. Each deployment target introduced friction and increased the risk of inconsistencies.
ONNX addresses this problem by introducing a clear separation between model creation and model execution. Instead of treating a trained model as framework-specific code, ONNX treats it as a portable representation of computation that can be consumed by different deployment systems.
How ONNX Represents a Model
ONNX represents a trained model as a computational graph. Rather than encoding executable source code, the model is expressed as a directed graph that describes how data flows through a sequence of mathematical operations.
Each node corresponds to a well-defined operation, such as matrix multiplication, convolution, or an activation function like ReLU. The edges represent tensors flowing between operations, including runtime inputs, intermediate results, and trained parameters such as weights and biases.
This representation is intentionally minimal and declarative. It describes the mathematical structure of the model—what operations are performed and how they are connected—without encoding training logic or framework-specific abstractions. As a result, the graph specifies what computation must occur, not how it should be executed on a particular piece of hardware.
Because data dependencies are explicit, ONNX graphs are well suited for analysis and transformation. They can be optimized or partitioned by downstream tools without changing the model’s semantics, which makes ONNX effective as an interchange format.
For a complete overview of supported operations, see the official ONNX operator documentation here:
ONNX as a Common Intermediate Representation (IR)
From a systems perspective, ONNX functions as a common intermediate representation (IR) for machine learning models. Similar to IRs in compiler design, it sits between high-level model definition and low-level hardware execution.
Training frameworks export models into ONNX, while deployment runtimes and optimization tools consume them. Because ONNX is standardized, transformations such as operator fusion, graph rewriting, or hardware-specific lowering can be applied consistently, regardless of the originating framework.
The ONNX model itself is stored as a .onnx file, which is a binary format based on Protocol Buffers. Protocol Buffers are a language-neutral, platform-independent serialization format designed to efficiently encode structured data. Compared to text-based formats, they produce compact binaries, load quickly, and support forward and backward compatibility through well-defined schemas.
At a structural level, this intermediate representation has a clear internal hierarchy. The top-level container, ModelProto, holds global metadata and references the computation graph. The graph itself, represented by GraphProto, defines inputs, outputs, trained parameters, and the connections between operations. Individual operations are described by NodeProto elements, each declaring an operator type along with its inputs, outputs, and attributes.
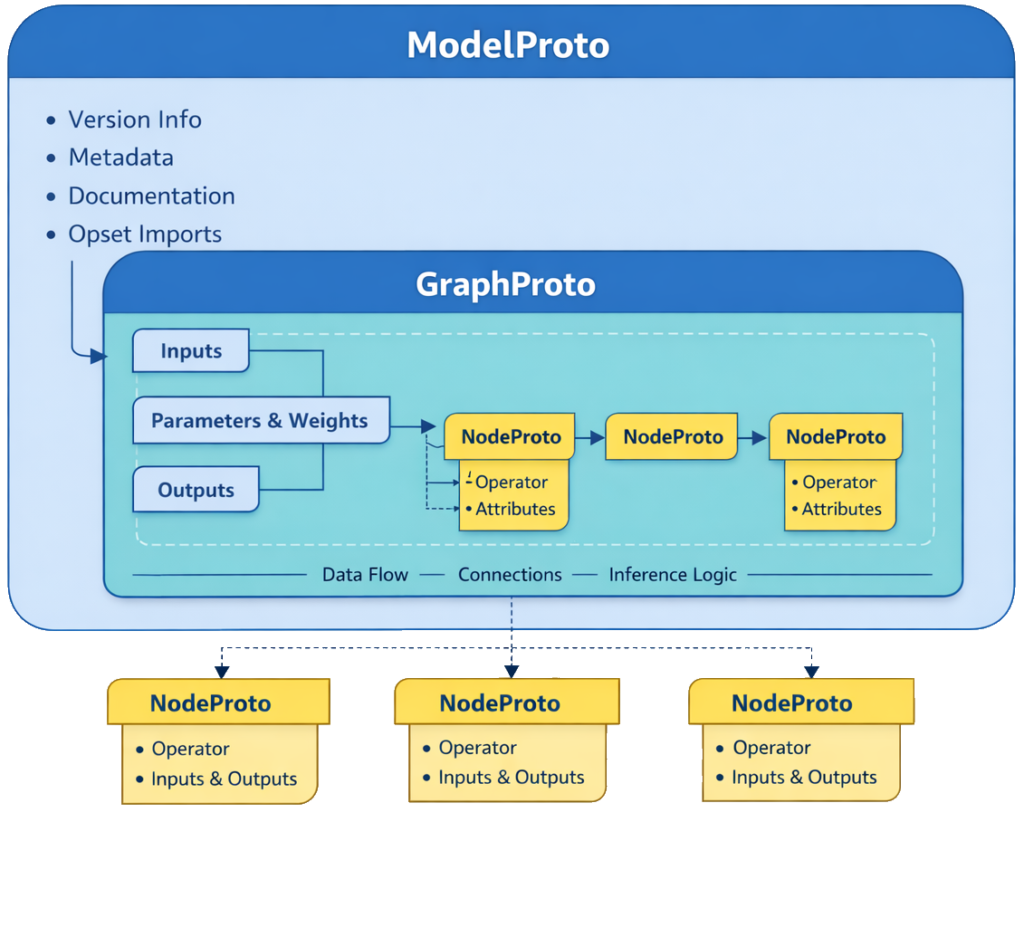
Together, these schema elements form a complete and portable description of a trained model that can be serialized, analyzed, optimized, and executed consistently across different platforms.
To make this structure tangible, the accompanying repository includes a small Python inspection script that loads an ONNX model and prints its structural anatomy. The script called ONNX-Inspector (see here on Github) exposes model metadata, opset dependencies, optional advanced fields, and a high-level summary of the computation graph. This allows readers to explore real .onnx files without executing the model or relying on the original training framework.
For more details on the ONNX IR, see the official specification here.
ONNX vs. ONNX Runtime: Clearing the Confusion
ONNX and ONNX Runtime are closely related but serve different purposes.
ONNX is a specification and file format. It defines how a trained model is represented, which operators exist, how tensors flow through a graph, and how this information is serialized. ONNX itself does not execute models.
ONNX Runtime is an execution engine. It consumes ONNX models, analyzes their graphs, applies optimizations, and executes them efficiently on hardware such as CPUs, GPUs, or NPUs.
ONNX defines what the model is. ONNX Runtime determines how it runs.
This separation allows training frameworks and deployment runtimes to evolve independently while interoperating through a stable, shared contract.
Final Thoughts
ONNX is often encountered indirectly, hidden behind tools, platforms, and runtimes that make modern AI systems feel seamless. Yet, as this article has shown, ONNX is not a minor implementation detail or just another model file format. It is a foundational abstraction that addresses one of the most persistent challenges in machine learning engineering: the gap between how models are trained and how they are deployed.
By representing trained models as computational graphs with well-defined operators and parameters, ONNX provides a stable and portable description of model behavior. Its role as a common intermediate representation allows training frameworks, optimization tools, and execution runtimes to evolve independently while still interoperating through a shared contract.
Understanding the distinction between ONNX and ONNX Runtime becomes increasingly important as deployment environments diversify, spanning cloud servers, edge devices, and specialized accelerators. Even if you never interact with ONNX directly, understanding its role helps explain why modern AI stacks are structured the way they are—and why standards like ONNX are essential for scaling machine learning beyond experimentation and into production.



