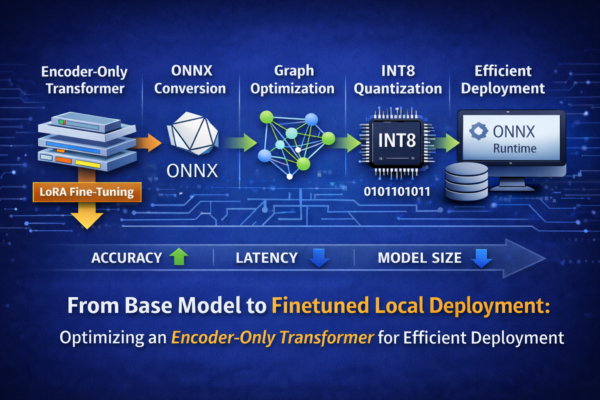
In this article, I walk through the complete deployment pipeline of an encoder-only Transformer model for text classification—from LoRA-based fine-tuning to ONNX conversion, graph optimization, and quantization. Each stage is analyzed in terms of its impact on accuracy, latency, and model size. The focus is on true local deployment: running a hardware-aware classification model entirely on local infrastructure using ONNX Runtime